
You hear about big data, extracting insight from social media and online content, but ever wondered how is it done?
[themify_box style=”gray rounded” ]This is a guest post by Ran Geva, Co-Founder & CTO of Buzzilla.[/themify_box]
In this post, I will briefly go over the 3 basic steps using 3 services and technologies to extract, index and analyze big data. Let’s say that we want to analyze what people are saying about Android OS related issues.
Step 1 – Data Extraction
If you want to extract insights from the web, you first have to obtain the data you want to analyze. It could be anything from news articles, discussions threads to reviews and blog posts. I recommend using Webhose.io to extract the data (disclaimer: I’m one of its founders) as it offers clean and strcutred live data that you can filter either by a query, source type, language and more. The crawlers behind Webhose.io crawl hundreds of thousands of public sources, downloading millions of posts a day, so you can get access to a vast amount of data. To achieve our goal, we will need to search for discussion posts (from forums) in English, taking place in site sections where the section title contains the keyword “Android”.
Using the Webhose.io search wizard, we will produce an API endpoint that will look like this:
https://webhose.io/search?token=<Access-Token>&format=json&q=thread.section_title%3A(android)&language=english&site_type=discussions
This will provide a JSON formatted output that we will need to index.

Step 2 – Indexing the data
When you deal with gigabytes of data and want to be able to sift and search through it, you have to index it in a search engine. This step isn’t mandatory for our example, as we already searched and filtered the data, but nevertheless, I will briefly go over some solutions.
There are a few simple “Search as a Service” solutions that you can use to store and index your data online:
- Amazon CloudSearch – a fully-managed service in the cloud that makes it easy to set up, manage, and scale a search solution
- SearchBlox – out-of-the box search solution
- IndexDen – Full-Text Search as a Service (might close their gates soon though)
There are other solutions that require installation and coding:
- ElasticSearch – Open Source Distributed Real Time Search
- Solr – Open source enterprise search platform
If the project you are working on is going to scale up, I suggest using either ElasticSearch or Solr. If you are creating a proof of concept, a small scale project, then I suggest using a hosted service, as it is much easier to setup.
Step 3 – Analyzing the data
To begin to understand what is being said around the “Android” topic, you need to extract the discussed entities, and the sentiment around them. I suggest using Semantria to extract the important entities and their sentiment, along with themes and categories. To understand what Semantria does, you can use their simple demo page.
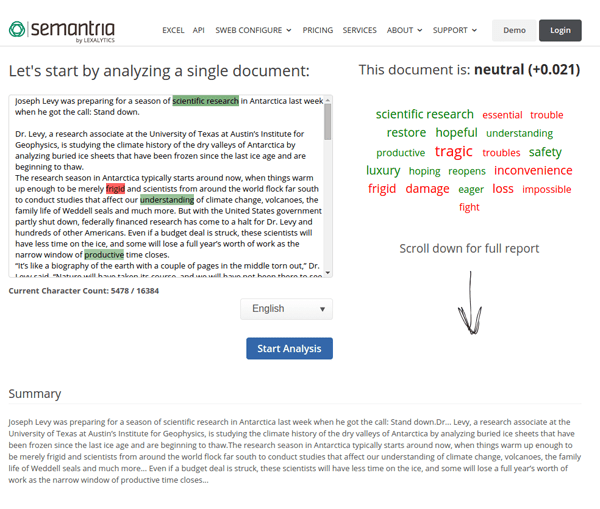
You could also reverse the order of step 2 and 3, and before indexing a post, extract the post sentiment, entities and themes. By doing so, you can later-on search and find only posts containing certain entities with a specific sentiment.
Summary
The 3 steps I wrote about, are a must have when you want to analyze big data, but it’s far from being the whole story. For complicated jobs that may take a lot of time, you may want to utilize an Hadoop cluster to distribute the work. You may also want to integrate internal business data on top of the web data you obtained, to cross reference and detect trends. Big data is much bigger than described in this post, but I hope I helped just a little to better understand some of the processes involved.